引言:2025年世界人工智能大会(WAIC)的热议背后,工厂大模型的“90%失败率”预言为工业智能化泼下一盆冷水。尽管资本与技术厂商热情高涨,但工业领域的严苛逻辑揭示出深层矛盾:数据多模态治理难、模型实时性与准确性失衡、商业价值难以量化。若无法跨越这些鸿沟,工厂大模型或将重蹈消费互联网领域AI项目的覆辙,成为昂贵却低效的摆设。本文剖析三大核心困境,探索工业智能从“花瓶”到“利器”的破局路径。
政策背景:实现中小企业的数字化转型,不仅是为了适应新型工业化的需求,更是对国家推进制造业数字化转型战略的具体实践。在习近平新时代中国特色社会主义思想的指导下,该方案着重于结合企业设备更新和技术改造,全面提升中小企业数字化水平。
总体目标:到2027年,方案计划通过“百城”试点推动全国中小企业的数字化转型,设定了明确的上云率、数控化率及其他数字化能力指标,为中小企业创造一个高效的转型生态环境。
刚刚落幕的2025世界人工智能大会(WAIC)上,关于工厂大模型和工业智能的讨论热度几乎达到顶点。各大厂商纷纷展示最新技术成果,描绘出一幅由AI驱动的高效智能工厂蓝图。然而,在这场技术狂欢与资本追捧的热潮中,一个令人警醒的预测正在业内悄然流传:未来投入应用的工厂大模型项目中,有90%可能无法实现预期价值,沦为昂贵而低效的”数字花瓶”。
这并非危言耸听。尽管没有专门针对工厂大模型失败率的官方统计,但更广泛的AI项目失败率数据早已敲响警钟。有研究报告指出,高达80%的AI项目以失败告终;另有数据显示,企业AI大模型落地应用的失败率也高达70%。当这股浪潮席卷到逻辑严密、流程复杂的工业领域时,失败风险只会被进一步放大。我们必须冷静思考,拨开喧嚣迷雾,审视那些可能导致工厂大模型沦为”数字花瓶”的深层技术与价值困境。
“数字花瓶”的诞生
所谓“数字花瓶”,并非指技术本身无效,而是指技术应用与工业现场的核心价值创造过程脱节,系统虽存在却无法融入生产节拍,无法形成业务闭环,最终成为一个仅供展示、无法产生实际业务增益的”摆设”。这种现象的背后,是三大难以逾越的鸿沟。
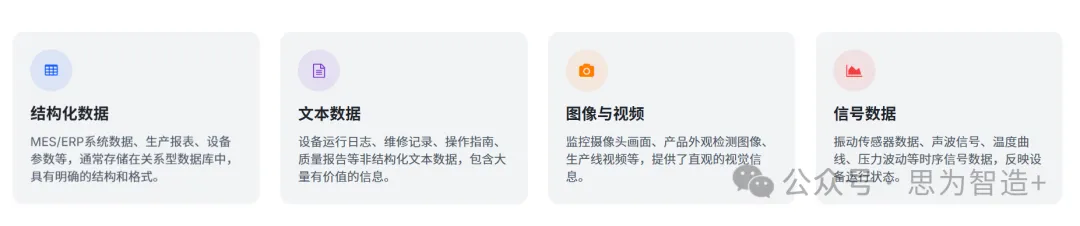
数据的”七寸:质量与多模态的枷锁
工业场景是数据的富矿,但更是数据治理的沼泽。工厂大模型的成功与否,首先取决于其脚下的数据地基是否稳固。然而,现实却异常骨感。
首先是数据质量的巨大波动。工业现场的数据源自成千上万的传感器、设备和系统,其质量不稳定会直接影响工业大模型的运行稳定性。一个微小的传感器漂移或错误的数据标签,都可能导致模型做出灾难性错误判断。其次是数据的多模态复杂性。工业数据天然就是多模态的,涵盖了结构化的MES/ERP数据、非结构化的设备运行日志、图像、视频、振动声波信号等。将这些来自不同来源、格式迥异的数据进行有效融合与对齐,本身就是一个巨大的技术挑战。目前,跨模态特征空间映射的误差高达15-20%,且缺乏坚实的数学理论支持,这使得工厂大模型在理解复杂的工业语境时常常力不从心。
更重要的是,数据治理与隐私风险始终是悬在头顶的利剑。核心工艺数据是制造企业的生命线,如何在使用大模型提升效率的同时,确保数据安全与合规,是每一个决策者都必须面对的难题。数据处理的种种难题,构成了工业大模型部署的首要技术壁垒。
模型的”水土不服”:实时性与准确性的两难
通用大模型在消费互联网领域的成功,并不能简单复制到工业领域。工厂大模型面临着严苛的”水土不服”问题。
实时性是第一道关卡。 工业控制系统往往要求毫秒级的响应速度,但大模型庞大的计算量导致其响应时间延长,难以满足高实时性要求。一个需要数秒才能反馈结果的质量检测模型,在高速运转的产线上几乎没有实用价值。同时,千亿参数模型惊人的能耗(单次推理耗电可达2.3kW)也让许多工厂望而却步。
兼容性是第二道关卡。 大模型与工业现场千差万别的硬件设备集成时,兼容性成为一个核心痛点。不同设备的计算资源、操作系统和数据传输协议各不相同,极大地限制了工厂大模型的部署范围和计算性能。
准确性与可靠性是最终的考验。 当前,大模型的”幻觉”问题和可解释性不足依然突出。在要求绝对精准的工业场景中,一个”幻觉”指令可能导致整批产品报废甚至引发安全事故。评测报告显示,即便是顶级的通用大模型,在面向实际工程的代码生成、科学计算、工业质检等场景中,准确性也远未达到理想状态。这种不确定性,使得企业难以将核心生产环节完全托付给工厂大模型。
价值的”ROI黑洞”:成本与产出的失衡
任何技术最终都要回归商业本质,即投入产出比(ROI)。而这恰恰是当前绝大多数工厂大模型项目最模糊的地带。
一方面,成本是明确且高昂的。大模型的训练、推理、私有化部署以及长期的运营维护,都需要巨大的资金投入。一次模型训练的成本可能高达数百万甚至上千万美元,这对于绝大多数制造企业,尤其是中小企业而言,是一个沉重的负担。
另一方面,产出却是模糊且难以量化的。许多工厂大模型项目在立项之初,就缺乏清晰、可量化的价值评估指标。项目前期的投入产出比难以清晰衡量,这直接阻碍了应用的深入实施。当一个项目无法用节省的成本、提升的良率或缩短的周期等硬指标来证明自身价值时,它就极有可能在管理层的质疑声中,从一个被寄予厚望的创新项目,异化为一个仅供参观的”数字花瓶”。此外,兼具算法能力与工业知识的复合型人才供需严重失衡,也进一步推高了项目的隐性成本和失败风险。
逃离”花瓶”陷阱
要避免工厂大模型成为”数字花瓶”,核心在于转变范式——从“我需要一个大模型”的技术驱动思维,转向“我需要解决什么问题”的价值驱动思维。我们必须建立一套有效的”花瓶鉴别标准”,或者说,是价值实现路径的评判准则。
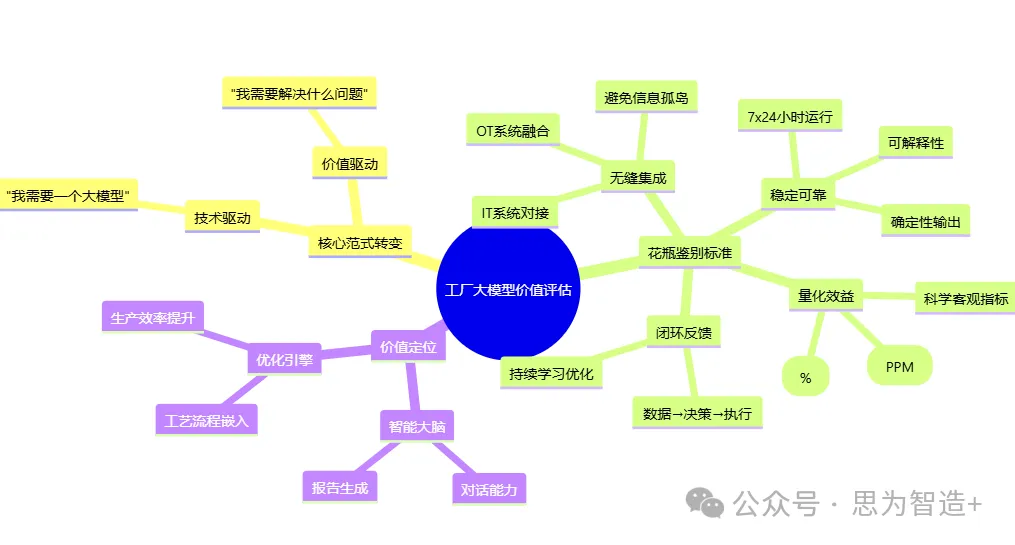
一个真正有价值的工厂大模型,不应仅仅是能够对话或生成报告的”智能大脑”,而应是深度嵌入到工艺流程中的”优化引擎”。它的价值不在于模型参数有多大,而在于它能否满足以下几个核心要求:
🔹闭环反馈: 它是否能将分析洞察转化为可执行的控制指令,并对执行结果进行再次学习,形成从数据到决策再到执行的完整闭环?
🔹量化效益: 它的应用效果是否能被明确量化?是能耗降低了百分之几,还是产品缺陷率减少了几个PPM?这些指标应遵循科学、全面、客观的原则。
🔹无缝集成: 它是否能与现有的OT(操作技术)和IT(信息技术)系统无缝集成,而不是成为一个游离于生产体系之外的信息孤岛?
🔹稳定可靠: 它在真实、复杂的工况下,能否保证7×24小时的稳定运行,并提供确定性、可解释的输出?
WAIC的热潮之下,我们更需要冷峻的思考。工厂大模型的未来,不在于构建更大、更全的模型,而在于能否用最经济、最可靠的方式,解决生产现场最具体、最棘手的问题。企业投入巨资,不是为了购买一个最新潮的”数字花瓶”来装点门面,而是为了获得一把能够真正降本增效、提升核心竞争力的”利刃”。
当喧嚣散去,潮水退去,那些无法证明自身价值、无法融入业务血脉的工厂大模型,终将被遗忘在布满灰尘的服务器机柜中。而真正的胜利者,将是那些让技术”消失”在场景里,默默创造价值的践行者。

声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:sales@idmakers.cn删除,任何个人或组织,需要转载可以自行与原作者联系。