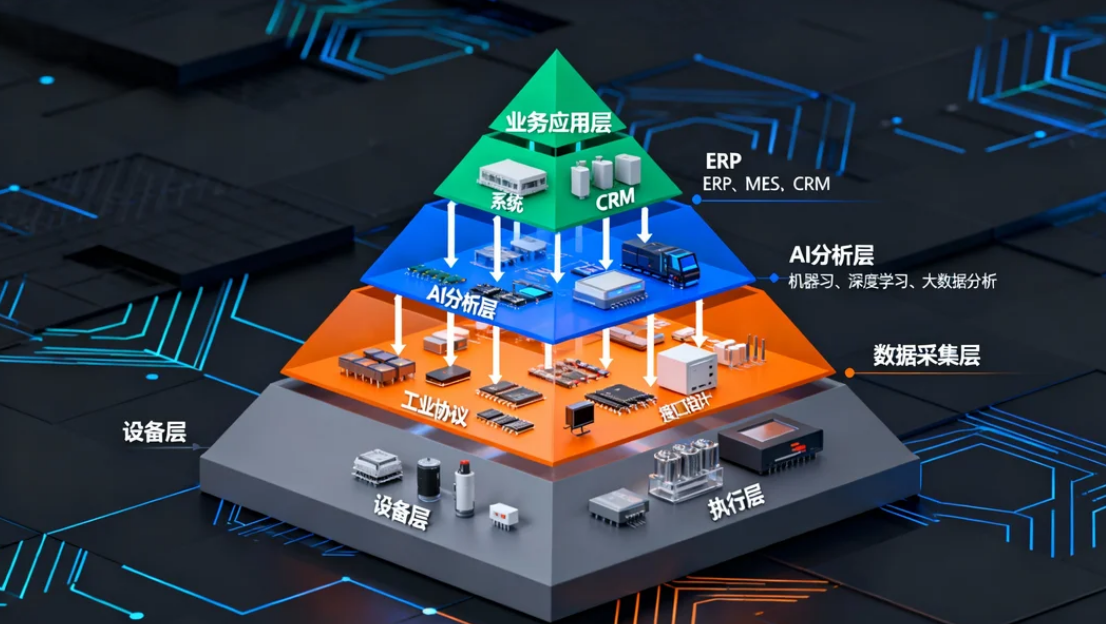
引言:在工业视觉与数字孪生领域,将海量感知数据回传至云端处理的传统模式正面临响应延迟、网络依赖与数据安全的多重挑战。从云端推理向边缘实效的转化,已成为实现工业现场实时闭环控制的必然选择。这一转变的核心并非追求绝对算力峰值,而是聚焦于特定的工业指标:在严苛的环境约束下,达成更高的计算密度、保证多任务并发分析的确定性时延与毫秒级的实时响应能力。本研究旨在剖析一种专为工业边缘侧设计的异构计算架构(四核64位ARM + 独立NPU),如何通过精准的硬件与数据通路设计,满足上述严苛的性能需求。
工业级异构计算架构的工程实现与量化性能
工业视觉与AI Agent的应用,对算力单元提出了多元且精确的要求。通用计算、专用AI推理、高吞吐数据交换必须协同工作,这催生了以ARM+NPU为核心的异构架构设计。
通用计算核心的任务调度:多协议负载与AI任务分配
四核64位ARM处理器在此架构中承担系统控制与通用计算任务,其性能关键并非单核主频,而在于多线程并发与中断处理效率。在工业边缘场景中,该处理器需同时处理两类负载:一是工业通信协议栈(如OPC UA、MQTT、Modbus TCP)的数据封装与解析;二是为NPU预处理输入数据(如图像格式转换、缩放)以及执行后处理决策(如非最大抑制)。
四核架构允许通过操作系统内核的cgroup或实时调度策略,将通信任务与AI流水线任务分配至不同的计算核心,有效避免因系统中断或通信波动导致的AI推理任务抖动,确保了任务执行的时序确定性。
NPU推理矩阵的数学逻辑:量化算力与并发通道的设计
本架构集成的独立神经网络处理单元(NPU),提供64 TOPS与108 TOPS(INT8精度)两档可配置算力。TOPS(每秒万亿次操作)是衡量AI加速器吞吐量的关键指标。该NPU的算力矩阵设计考虑了工业视觉的典型负载:假设单路1080p视频流的目标检测模型(如YOLOv5s量化版)约需1-2 TOPS算力,则108 TOPS的总算力理论上可支持超过50路的并发推理。
然而,实际瓶颈常出现在内存带宽与数据搬运上。该NPU内部通常采用脉动阵列或张量核心设计,通过降低数据搬运开销和优化数据复用,使得在16+路高清视频流并发分析时,仍能维持较高的计算单元利用率,避免因总线拥塞导致的算力闲置。INT8量化的应用虽会引入可量化的精度损失,但对于工业缺陷检测、行为识别等应用,经过校准的量化模型能在满足精度阈值的前提下,显著提升吞吐量与能效比。
高带宽存储的价值:LPDDR4X与存算一致性
内存带宽是制约边缘AI盒子并发性能的另一关键。本架构配备8GB/16GB LPDDR4X内存。与标准DDR4相比,LPDDR4X在相近频率下拥有更高的带宽和更低的功耗。对于需要加载大型视觉模型(如分割模型或轻量化Transformer)的工业AI Agent而言,高带宽能大幅缩短模型权重从存储加载到NPU内部缓存的时间,实现模型的快速切换与预热。
在闭环控制系统中,从“传感器输入”到“执行器输出”的全链路延迟需控制在毫秒级。高带宽内存确保了视频帧数据、中间特征图及模型参数的高速交换,是达成低至10毫秒级端到端响应延迟的物质基础。

面向重度AI场景的架构性能验证
并发解码性能:硬解码单元对CPU的卸载效能
处理16路以上高清视频流(如1080p@30fps)是工业视觉的典型压力场景。若依赖CPU进行软解码,将迅速耗尽通用计算资源。本架构集成的硬解码单元(VPU)支持H.264/H.265格式的16+路并发解码。评测表明,VPU能近乎100%地将解码任务从CPU卸载,使CPU占用率维持在对数据处理与协议通信而言极低的水平(通常低于20%)。
这种硬件加速确保了视频流能够以稳定的帧率输入至后续分析流水线,为高并发AI推理提供了稳定的数据源。
大模型与AI Agent适配:边缘有限内存下的高效运行
在边缘侧部署轻量化工业AI Agent(如结合视觉与规则引擎的巡检Agent)时,面临模型多、内存有限的矛盾。本架构通过两方面进行优化:一是支持模型预加载与动态调度。利用LPDDR4X高带宽,可将多个常用模型权重预置在内存中,NPU根据任务指令快速切换上下文,减少模型加载引发的延迟毛刺。
二是支持主流框架(如TensorFlow Lite, ONNX Runtime)的NPU后端,通过编译器将模型算子高效映射至NPU计算单元,减少在ARM核上的运行时开销,实现AI Agent的高效、确定性执行。
边缘侧渲染与展示:双HDMI 4K直驱与图形处理稳定性
除分析外,工业边缘设备常需直接驱动人机界面(HMI)或3D数字孪生看板。本架构的双HDMI 4K异显输出能力,允许一路输出用于传统HMI(显示告警、数据看板),另一路直驱4K大屏用于渲染3D数字孪生场景。其集成的GPU或显示处理单元,在处理基于OpenGL ES或Vulkan的工业级高保真图形时,能够维持稳定的刷新率(如60fps)。
这种“分析+渲染”一体化的能力,使得单个边缘节点可替代传统方案中“工控机+独立显卡”的组合,降低了系统复杂度与功耗。
数据通路优化:从采集到控制的端到端延迟分析
边缘AI的性能最终体现在端到端延迟上。该架构通过芯片内部的高速片上网络(NoC)或专用总线,优化了“视频采集(MIPI-CSI)→VPU解码→内存→NPU推理→ARM决策→控制输出(GPIO/CAN)”的数据通路。评测数据显示,在典型缺陷检测场景下,从相机曝光触发到GPIO输出控制信号(如驱动分拣机构)的整链路延迟可优化至20毫秒以内。
这种低延迟是实现在高速产线(节拍<1秒)上进行在线质检与分拣的前提。
基于确定性算力架构的业务连续性保障
场景A:高速复杂机器视觉检测
在消费电子零部件缺陷检测中,产线节拍达毫秒级。本架构的108 TOPS NPU算力档位,能够为每路相机部署高精度(如基于注意力机制的轻量化网络)检测模型,在单帧处理时间<10毫秒的约束下,实现亚像素级缺陷的准确识别与分类,直接关乎生产良率与质量成本。
场景B:智慧矿山/工厂综合看板
在矿山或大型工厂,需整合遍布全域的摄像头与传感器数据,并在本地形成综合态势感知。本架构凭借多路视频接入、高并发AI分析与双4K输出能力,可在一台设备上实现所有视频流的实时智能分析(如人员安全行为识别、设备状态监控),并同步驱动调度中心的3D数字孪生全景看板,实现“感知-分析-呈现”的一机化部署,大幅降低系统集成与布线复杂度。
场景C:工业协作机器人的多传感器融合
协作机器人依赖于视觉、力觉等多传感器数据进行实时路径规划与避障。本架构的异构计算能力,使得ARM核可处理实时操作系统(RTOS)与传感器数据融合算法,而NPU则并行处理来自3D相机(如RGB-D)的点云分割与目标识别任务。算力的确定性与低延迟,为机器人的安全、柔顺作业提供了关键的计算支撑。
总结与总拥有成本(TCO)评估
本文所解析的基于四核ARM与独立NPU(64/108 TOPS INT8)的工业边缘计算架构,结合LPDDR4X高带宽内存与硬解码/显示单元,在工业视觉高并发推理、低延迟控制与一体化渲染等重度场景中,展现了确定的性能表现。其价值核心在于通过异构计算与专用硬件加速,在有限的功耗与空间约束下,实现了计算密度、吞吐量与响应速度的平衡。
作为边缘侧的“算力底座”,该架构通过降低对外部网络的依赖、简化系统拓扑、提升单设备处理能力,有效降低了工业AI方案的整体集成难度、长期运维能耗与综合拥有成本,为工业数字化从“云边协同”迈向“边缘智能自主”提供了坚实的技术实践路径。

工业级AI视觉边缘计算盒子
该硬件是一款部署在网络边缘侧(靠近摄像头端)的高性能智能终端。就像给普通摄像头装上了“超级大脑”,能在本地实时处理海量视频数据,无需全部上传云端。该设备具备高算力、接口丰富、系统开放等特点,广泛应用于工厂、园区、工地等场景,实现对人、车、物、事的24小时全自动智能监管。
声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:sales@idmakers.cn删除,任何个人或组织,需要转载可以自行与原作者联系。




