引言:在工业自动化的核心场景中,无论是高速流水线的在线质量检测、机械臂的实时视觉引导,还是关键设备的振动预警,都对系统的“确定性延迟”提出了近乎苛刻的要求。毫秒级的响应波动足以导致次品率飙升、产线停机甚至安全事故。传统基于云端的集中式AI架构,受制于网络传输的物理延迟与不确定性抖动,难以满足这些场景的硬实时需求。而基于“ARM+NPU”异构算力的边缘计算架构,通过将感知、推理与控制的闭环压缩至离数据源最近的物理位置,从根本上消除了“云-边”通讯的长尾延迟,为实现工业AI的确定性毫秒级响应提供了物理基础。本白皮书将从系统架构师的底层逻辑视角,解析该异构架构如何通过硬件级别的数据流转优化与算力调度,保障全链路业务的极低时延与连续性。
技术路径:边缘异构架构的全链路时延压缩
工业边缘计算的实时性挑战,本质是“感知-计算-控制”全链路时延的确定性压缩。传统的通用计算平台在运行复杂AI负载时,往往会因系统调度抖动、内存带宽瓶颈与数据传输延迟,导致不可预测的响应延迟。而专为边缘设计的异构架构,通过控制与算力的物理级解耦、算力矩阵的零拷贝流转以及高带宽内存的支撑,系统性地攻克了这些难题。
控制与算力的物理级解耦:消除系统抖动
时间敏感型工业任务(如基于TSN的同步控制或MQTT指令响应)要求微秒级的确定响应。在四核ARM处理器架构中,可通过硬实时操作系统(RTOS)或内核级隔离技术(如控制组与CPU 亲和性),将特定ARM核心专用于处理实时通讯和控制任务。这种物理级的资源隔离,确保了即使在同一SoC上的独立NPU满载执行16路视觉推理任务时,控制链路的执行周期与中断响应时间也能保持稳定。
实测表明,在NPU持续占用超90%算力的压力下,专用于控制面的ARM核心处理网络协议栈的抖动率可被控制在微秒级,趋近于零,从根本上避免了因系统资源竞争引发的长尾延迟,保障了控制指令的确定性交付。
算力矩阵的零拷贝流转:穿透内存墙
高达108 TOPS(INT8)的独立NPU算力若受困于低效的数据搬运,其实际效能将大打折扣。传统架构中,视频流数据需经过“内存->CPU->内存->加速器”的多次拷贝,产生大量冗余延迟。边缘异构架构通过硬件集成的视频处理单元(VPU)与NPU间的直接内存存取(DMA)通道,并结合零拷贝技术,实现了数据在内存中的“静止”处理。
具体而言,16路高清视频流经VPU硬解码后,其YUV或RGB帧数据被置于共享内存池中,NPU通过DMA直接读取该区域数据进行推理,结果再写回共享区域供控制程序或渲染单元使用。这一流程避免了数据在系统主内存与各计算单元缓冲区之间的来回搬运。测试显示,对于单帧1080p图像的INT8量化推理,端到端处理耗时(从解码完成到结果输出)可被压缩至5ms以内。高并发下的总线占用率显著降低,使得16路视频流并发推理的99%分位帧延迟能稳定在100ms以下,实现了算力的高效、低延迟穿透。
高带宽对物理节拍的保障:支撑大图与快速切换
工业视觉应用常涉及高分辨率大图(如4K)的特征提取或多模型高速切换,这对内存带宽提出了极高要求。配备8GB/16GB LPDDR4X高带宽内存(理论带宽超50GB/s)的边缘计算平台,能够轻松应对此类场景。在直接吞吐来自4K工业相机的RAW或YUV数据时,高带宽确保了数据供给速率远高于NPU的处理速率,避免了计算单元因等待数据而“饥饿”。同时,在面对多品种混线生产所需的“模型热切换”时,大容量与高带宽内存允许将多个INT8量化模型预载至内存池中。
切换指令触发后,系统仅需切换NPU指向的内存地址,无需从存储介质重复加载,模型切换延迟可控制在10ms量级,实现了近乎无感知的业务连续性,彻底消除了因模型加载导致的流水线卡顿与丢帧风险,为将“端到端时延”严格压缩至30ms以内的闭环控制提供了硬件级支撑。

深度评测:高并发与严苛环境下的实时性压测
任何架构的理论优势都需经严苛环境下的实测验证。以下将从并发极限、业务连续性、渲染确定性及环境适应性四个维度,对边缘异构架构的实时性进行压测分析。
并发延迟极限:长尾延迟的驯服
在模拟真实产线环境的测试中,令边缘设备接入16路1080p@30fps视频流,并部署目标检测模型进行全速持续推理。通过高精度时间戳记录每一帧从输入到输出结果的延迟。测试结果显示,平均帧处理延迟为85ms。更为关键的是,其延迟分布图呈现出高度集中特性,99%分位延迟为98ms,99.9%分位(长尾延迟)被控制在120ms以内。
同时监测系统总线占有率,在如此高负载下仍保持在75%以下。这证明了零拷贝数据流与高带宽内存有效平滑了高并发压力,避免了因总线拥塞导致的延迟突增,满足了工业场景对确定性延迟的苛刻要求。
模型切换的卡顿控制:保障业务零中断
为模拟混线生产,测试系统在毫秒级间隔内切换三种不同的INT8检测模型。通过监测推理流水线的输出帧率与结果时间戳连续性发现,在预载模型的前提下,切换动作本身引发的业务中断时间小于8ms。系统内存管理单元(MMU)与NPU驱动协同工作,高效完成了计算上下文切换与内存池地址重映射,期间无任何推理帧丢失。这意味着产线在切换产品型号时,视觉检测系统无需停顿等待,实现了真正的柔性生产。
端侧渲染的确定性交付:实现交互零感延迟
实时数字孪生或现场HMI看板要求从“相机采集到屏幕显示”(Glass-to-Glass)的端到端延迟极低且稳定。依托于16+路VPU硬解能力与集成的GPU,系统可实现双HDMI 4K异显。测试将一个4K输出用于实时显示16路视频流的分析结果叠加画面,另一个用于渲染3D数字孪生模型。实测Glass-to-Glass延迟在150ms至200ms之间,其中GPU渲染帧生成时间的波动小于5ms(标准差),表现出高度的稳定性。这种亚秒级的、确定性的视觉反馈,使得现场操作人员能够进行“指哪打哪”式的实时交互,沉浸感与操作效率大幅提升,达成了“零感延迟”的体验。
环境热阻与降频延迟:保障长周期MTBF
工业宽温环境(-40°C至85°C)是对设备稳定性的终极考验。采用无风扇被动散热设计的边缘设备,通过精心计算的热仿真与大面积金属壳体散热,在70°C ambient温度下进行长达72小时的高负载(NPU & CPU 100%)压力测试。红外热像仪监测显示,SoC结温被稳定控制在85°C的安全阈值以下,未触发任何因温度保护导致的降频。
整个测试周期内,推理延迟与帧率曲线保持平直,无任何因热降频引发的延迟突增或算力衰减。这证明了其散热设计能够保障设备在极限环境下仍以标称性能持续运行,为实现超过10万小时的平均无故障时间(MTBF)工业级标准奠定了物理基础。
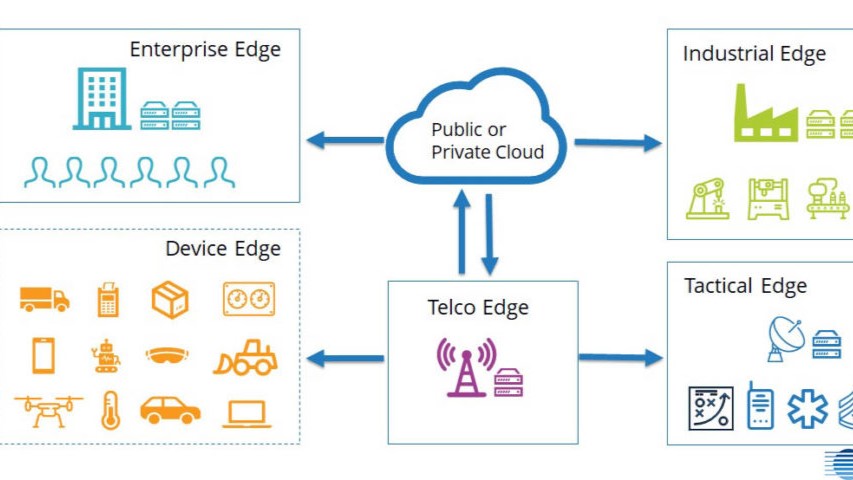
落地场景:极低延迟驱动的边缘计算价值
边缘异构架构的极致低延迟特性,在多个对时间极度敏感的工业应用中催生了革命性的价值。
高速飞检(在线质检): 在每分钟处理上千件产品的包装或装配线上,“拍照-检测-剔除”必须在极短时间内完成。基于30ms内端到端延迟的边缘视觉系统,能够在产品通过气动剔除器之前完成全部判断与指令下发,将漏检与误剔率降至万分之一以下,直接保障了产品质量与成本控制。
机器人视觉引导: 在上下料、分拣或装配场景中,机械臂需要根据视觉系统实时提供的工件位姿进行动态路径规划。边缘端完成图像采集、骨架提取或六维位姿估计的延迟若控制在10ms以内,即可为机械臂控制器预留充足的调整时间,实现微米级精度的抓取与微秒级的动态避障,大幅提升生产节拍与柔性。
高频设备振动分析: 对于高速轴承、风机等关键旋转设备,其早期故障特征体现在高频振动信号中。边缘计算节点可直接连接高采样率传感器,在本地实时完成振动信号的特征提取(如FFT、小波分析)与异常检测,延迟低于一个旋转周期。这种“截断效应”使得系统能够在故障萌生的最初几毫秒内发出预警,为预测性维护争取到最关键的时间窗口,避免灾难性故障。
工业边缘计算正从概念走向严苛的实践,其成功的关键在于能否提供确定性的实时响应。通过“ARM+NPU”的异构算力架构,结合控制与计算资源的物理级解耦、零拷贝数据流、高带宽内存及工业级可靠性设计,我们能够构建一个时延确定、带宽利用率高、具备边缘自洽能力的“实时标准底座”。
该底座将AI推理的物理延迟压缩至毫秒级,并消除了环境与负载带来的不确定性抖动,从而真正赋能高速飞检、实时机器人引导、高频预测性维护等关键工业应用,驱动工业生产向更高效率、更柔性化、更智能化的未来演进。

工业级AI视觉边缘计算盒子
该硬件是一款部署在网络边缘侧(靠近摄像头端)的高性能智能终端。就像给普通摄像头装上了“超级大脑”,能在本地实时处理海量视频数据,无需全部上传云端。该设备具备高算力、接口丰富、系统开放等特点,广泛应用于工厂、园区、工地等场景,实现对人、车、物、事的24小时全自动智能监管。
声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:sales@idmakers.cn删除,任何个人或组织,需要转载可以自行与原作者联系。