引言:在工业数据采集场景中,传统云中心化模式面临实时性不足、网络带宽受限、数据延迟高以及边缘智能缺失等核心挑战。大量工业现场需要毫秒级响应、本地预处理和断网自持能力,边缘计算因此成为解决这些问题的关键支撑。边缘计算通过在靠近设备的一侧构建计算节点,提供数据采集、清洗、存储、分析、控制等就近计算处理能力,从而打破IT与OT系统之间的数据壁垒,实现生产数据的低延时流转与高可靠处理。本文将从边缘计算数据采集的四大核心环节出发,系统阐述其实时采集、数据清洗、本地分析与闭环控制的技术价值,帮助工业用户全面理解边缘计算在数字化转型中的战略地位。
一、就近接入与实时性突破:边缘数据采集的核心能力
1.1 协议兼容与多源设备统一接入
工业现场设备通信协议标准不统一,是数据采集面临的首要障碍。边缘计算网关集成了丰富的协议解析引擎,支持超过200种主流工业通信协议,能够实现南向与各类传感器、PLC、机床、仪表等异构设备的快速对接。通过内置的驱动管理系统和底层操作系统,边缘节点可以将不同协议的数据统一转换为标准格式,从而消除协议壁垒,实现多源数据的实时采集。这种就近接入能力不仅降低了网络传输的延迟,还避免了对云端协议转换的强依赖,显著提升了数据采集的实时性与可靠性。
1.2 本地缓存与断网续传保障可靠性
工业环境中的网络波动是常态,边缘计算数据采集必须具备断网自持能力。边缘网关内置本地数据缓存机制,能够在网络中断时继续将采集到的数据暂存于本地存储介质,待网络恢复后自动进行断网续传。这一机制确保了生产数据的完整性和连续性,避免了因网络故障导致的数据丢失或采集中断。同时,本地缓存还支持数据的分级存储,将高频实时数据与低频历史数据分别管理,为后续的分析与控制提供可靠的数据基础。
二、提升质量与降低传输负载:边缘数据清洗与存储
2.1 实时数据降噪与格式标准化
工业现场采集到的原始数据往往包含噪声、重复、异常值等质量问题,直接上传云端不仅会消耗大量带宽,还会增加云端处理的复杂度。边缘计算节点在数据产生的第一时间即可执行实时数据清洗,包括去重、滤波、异常检测、格式转换等操作,从而完成数据降噪。经过清洗后的标准化数据,不仅质量显著提升,还大幅降低了需要传输的数据量,减轻了网络带宽压力。这一过程被称为“边缘数据治理”,是实现数据驱动决策的基础前提。
2.2 本地时序存储与压缩归档
边缘节点不仅承担数据清洗任务,还具备本地存储能力。针对工业数据的时间序列特性,边缘计算网关可内置时序数据库或轻量级文件系统,对清洗后的数据进行本地缓存归档。通过数据压缩、过期淘汰等策略,边缘存储能够平衡存储容量与数据保留期限,满足不同场景对历史数据回溯的需求。同时,本地存储也支持边缘分析引擎的实时读取,为后续的流式分析和本地控制提供数据支撑,避免了对云端存储的频繁访问。

三、实现本地智能与快速闭环:边缘分析与控制
3.1 流式分析实现毫秒级响应
边缘计算的核心理念是将计算能力下沉至数据源附近。通过在边缘节点部署流式分析引擎,可以对持续产生的数据流进行实时计算,例如趋势预测、阈值报警、模式匹配等。这种就近处理模式能够将分析延迟从云端通讯的数秒级缩短至毫秒级,满足设备联动、产线异常预警等高实时性要求。工业用户无需等待数据上传云端并返回结果,即可在本地获得分析结论,从而快速响应生产变化。
3.2 本地控制逻辑与边缘自治
边缘分析的结果可以直接触发本地控制指令,形成数据采集-分析-控制的闭环。边缘计算网关支持灵活的规则引擎配置,用户可以根据业务需求自定义控制逻辑,例如当温度超过阈值时自动启动冷却风扇,或者当振动异常时执行设备停机。这一能力使得边缘节点具备一定的自治能力,即便与云端断开连接,也能独立完成本地控制任务,确保生产过程的连续性和安全性。边缘自治的引入,不仅减少了云端决策的依赖,还提升了整个系统的容错能力和响应速度。
四、与云端互补的完整数据流:边缘协同价值
4.1 云边协同实现数据分级处理
边缘计算并非取代云端,而是与云端形成协同互补的关系。边缘节点负责处理需要低时延、高可靠和本地闭环的数据,而云端则聚焦于全局性、长期性的分析与应用,如设备全生命周期管理、大数据分析、AI模型训练等。通过云边协同架构,工业数据被分级处理:边缘侧完成实时采集、清洗、分析与控制,将经过处理的高价值数据摘要或异常事件信息北向上传至云端;云端则利用边缘侧提供的数据基础,开展更深层次的数据挖掘和业务优化。这种分工模式既发挥了边缘的实时优势,又保留了云端的计算规模与存储能力,形成了完整的数据流闭环。
4.2 灵活规则引擎支撑业务编排
边缘计算网关内置的规则引擎是云边协同的关键纽带。用户可以通过图形化或脚本化的方式灵活定义数据流的定向路由、触发条件与执行动作,实现消息在边缘与云端之间的智能流转。例如,将常规数据留在边缘本地处理,仅将异常报警或统计摘要上传;或将特定数据直接转发至公有云服务进行进一步分析。这种灵活的编排能力,使得工业用户能够根据实际业务需求动态调整数据分配策略,最大化利用边缘算力资源,同时降低云端的计算与存储成本。
综上,边缘计算数据采集通过“端-边-云”协同架构,从采集、清洗、存储、分析到控制,构建了完整的就近计算处理体系。它不仅解决了工业实时性、可靠性、数据质量和成本优化等核心痛点,更为智能制造、设备运维、质量追溯等高级应用提供了坚实的数据底座。理解并落地边缘计算的全栈能力,将成为工业数字化转型的关键一步。

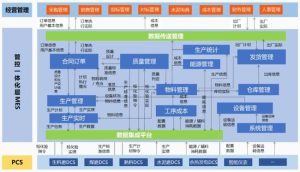
工业数据采集应用解决方案
工业互联网数据采集与应用解决方案采用“端-边-云”架构,提供设备接入、边缘计算、云端服务等全栈能力。支持海量设备高并发接入, 灵活适配各类工业协议。边缘侧提供数据采集、清洗、存储、分析、控制等就近计算处理。云平台提供设备管理、应用开发、数据服务等PaaS能力。为工业客户实现设备全生命周期管理,助力工业数字化转型。
声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:sales@idmakers.cn删除,任何个人或组织,需要转载可以自行与原作者联系。